多线程
-
线程的几种状态- 新建状态: Thread t = new MyThread()
- 就绪状态: thread.start()
- 运行状态
- 阻塞状态: wait(), sleep() 执行之后
- 死亡状态: 执行完或者抛出异常了
-
死锁产生的原因: 多线程对资源的竞争以及并发执行顺序不当 -
死锁的条件 破坏死锁的方法就是破坏下面的条件-
互斥原则: 一个资源一次只能分配给一个线程使用
-
不可剥夺条件: 一个线程不能强行占有其他线程已占有的资源
-
请求与保持原则: 一个线程在等待其他进程释放资源的同时,继续占有已经拥有的资源
-
循环等待条件: A 等 B, B 等 C, C 等 A
-
-
多线程如何同步- 使用 volatile 关键字并使用 Atomic(Boolean/Integer) 等对象, 保证数据多线程可见性(volatile)原子性(Atomic)
- 使用 synchronized 代码块或者 synchronized 关键字的函数 (也可ReentrantLock, ReadWriteLock), 既能保证数据的可见性, 又能保证原子性
CAS: 实现了高效的原子性操作, 缺点是ABA问题:- 线程1和2, 它们期望值均为A, 欲更新的值均为B
- 线程1成功执行, 但是线程2它卡了, 这时候出现了线程3, 把B更新为A
- 此时B执行的时候并不知道以及出现了
A->B->A这样的变化过程 - 解决方法是加上版本号:
1A->2B->3A
-
Handler-
干啥的: 在指定的运行中的线程执行任务
Handler.post干了啥? 就是将任务插入消息队列 -
Looper: 就是个死循环
-
prepare(): 在 ThreadLocal 中创建一个 Looper
-
loop(): 取出 Looper 对象中的MessageQueue进行消息循环
Message 本身其实是个链表, 有
what / arg1 / arg2 / obj/ when / callback / next等 -
-
分发消息:
msg.target.dispatchMessage, 先看传入的 Message 有没有 callback 其次调用当前 Handler 初始化时传入的callback.handleMessage最后尝试子类是否 override handleMessage -
坑: Handler 容易内存泄露, 但事实上所有的内部类都会这样, 此时我们应该选择持有外部类的弱引用并使用
WeakReference<>.get()来调用并判断是否为 null -
IdleHandler: Looper 循环中, MessageQueue 空闲时, 允许我们执行一些任务的机制(执行时机没有那么高要求的任务) -
同步屏障: 确保异步消息的优先级, 开启屏障后, 只能处理其后的异步消息, 同步消息会被挡住- 创建的原理: 创建了一个 Message 对象并加入到了消息链表, 但其
target 为 null, 可以使用handler.getLooper().getQueue().postSyncBarrier()来创建 - 使用
message.setAsynchronous(true)即可将任务变成异步的, 然后通过handler.sendMessage即可, 可以用handler.getLooper().getQueue()获取messageQueue, 之后调用removeSyncBarrier来移除同步屏障 - 啥地方用到了:
ViewRootImpl的performTraversals为了更快响应 UI 刷新事件就用了这玩意
- 创建的原理: 创建了一个 Message 对象并加入到了消息链表, 但其
-
MessageQueue的next方法是阻塞的, 但是为什么没有导致主线程卡死呢? 这里涉及到了nativePollOnce和nativeWake, 我个人理解他们类似于 Java 的那种object.wait()以及object.notify(), 但实现肯定是不一样的, 具体这里就涉及到了Linux底层的机制了 -
ThreadPoolExecutor(队列未满时的线程最大并发数 corePoolSize, 队列满了以后线程的最大并发数 maximumPoolSize, 线程空闲时间超过多少就回收 keepAliveTime, TimeUnit unit, 阻塞队列类型 BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, 超出maxPoolSize+queue大小时, 任务交给RejectedExecutionHandler handler)newFixedThreadPool: 指定线程池的大小, 空闲时间0, 无界阻塞队列newCachedThreadPool: corePool为0, 最大无限大, 延迟60s, 无空间阻塞队列newSingleThreadExecutor: 和 newFiexdThreadPool 线程池大小为1一样, 但会自动 shutdown()newScheduledThreadPool: 定时任务或延迟任务(scheduleAtFixedRate/scheduleWithFixedRate)
-
HTTP
-
常见状态码状态码 类别 作用/代表 1xx 信息性状态码 100 continue 2xx 成功 200 success
206 Partial Content3xx 重定向 301永久/302临时 4xx 客户端错误 400 Bad Request
401 Unauthorized
403 Forbidden
404 Not Found5xx 服务端错误 500/503 -
HTTP 1.0: 短连接 (100张图, 发起100次 TCP 握手挥手)HTTP 1.1: 长连接 (100张图, 一次 TCP 握手挥手, 在一个TCP连接上可以传送多个HTTP请求和响应)HTTP 2.0: 长连接 + IO 多路复用 (同时通过单个 HTTP/2 连接发起多重的请求-响应消息, 可以很容易实现多流并行而不依赖多个 TCP 连接) -
TCP/IP 协议族: 一系列协议组成的网络分层模型 (分层原因: 网络会不稳定, 交给下层让下层去处理这些事情, 让下层去做失败重请求等操作)客户端 传输 服务端 应用层(HTTP/FTP/DNS…) 应用层 传输层(TCP: 失败重连/UDP: 不重连<直播>) 传输层 网络层(IP): 路由, 寻址 网络层 数据链路层(物理层: 以太网/Wifi/光纤) <————> 数据链路层 -
计网的
七层协议: 就是把上面应用层分成了应用层(HTTP/FTP/SMTP…), 表示层(定义数据格式和加密), 会话层(定义如何开始结束一个会话…) -
URL组成: 协议://域名:端口/虚拟目录/文件名?参数1=值&参数2=值#锚点, 但部分是可以省略的, 比如说不同协议有默认端口, 就可以省略(HTTP:80, FTP:21, SSH:22, SSL/TLS/HTTPS:443) -
报文格式:
请求行: 请求方法 路径 HTTP版本 (回车)请求头: headers…请求体 -
HTTPS: 其实就是 HTTP 之下加了一层 TLS/SSL 协议(安全层)
原理: 通过非对称加密协商出一套对称加密的密钥, 然后采用对称加密达到加密传输 -
TCP/UDP:-
UDP无连接、开销小、速度快, 但存在丢包, 适用于音频/视频/直播这种偶尔丢失一两个数据包也没什么关系的 -
TCP通过三次握手确保建立好可靠数据连接才会进行传输, 以及采用了超时重传/错误校验等机制保证数据的可靠传输三次握手: 客户端:“我准备好了” 服务端:“我收到了 你开始吧” 客户端:“好的 那我开始了” 四次挥手: 客户端:“我发完了” 服务端:“我知道了” 服务端:“那你关闭吧” 客户端:“那我关了”
ACK机制: 客户端每次发送消息的时候会带上校验信息以及seq+1, 服务端收到后返回seq+2, 客户端发送seq+2的消息, 服务端收到后返回seq+3…. 但是为了提高性能, 往往服务端会等客户端发送几个以后再根据收到的最后一次客户端正确的消息的seq+1返回, 数据出现错误的时候也会重新返回出错的seq流量控制: 用来解决发送和接受速率不匹配的问题的. 然后接收方这边会维护一个接收窗口(表示接收方还有多少空间), 发送方不断发数据, 接收方不断消费数据, 窗口也会动态变化, 发送方只要控制发送内容是小于接收窗口大小的就可以达到流量控制的目的了(SWND(发送窗口),RWND(接收窗口),CWRD拥塞窗口)拥塞控制: 网络本身拥堵, 发送方不得不采取降低速率来避免网络更加拥堵. 有四种拥塞控制算法:慢开始,拥塞避免,快重传,快恢复
Tahoe: 接收到三个重复的 ACK, 阈值减半, 新窗口大小设置为1重新启动,Reno: 窗口减半, 然后拥塞避免 -
为什么
一定要三次握手?TCP 的可靠连接是靠起始序列号 seq(sequence numbers) 来达成的, 如果只有两次的话, 客户端发送了自己的序列号服务端进行确认, 而服务端发出的起始序列号客户端不能进行确认 (只能接受), 不能确保数据传输可靠性.
-
-
TLS 建立过程-
Client Hello -
Server Hello(包含加密套件<对称/非对称/hash> / 客户端随机数 / 服务端随机数) -
服务器证书信任建立 为了保证公钥的可信性会进行以下验证
服务端: 将服务器的信息(公钥/主机名/地区 等)进行 hash, 并用签发机构的私钥进行加密成签名
客户端: 将服务器发来的信息进行hash, 并用签发机构公钥(也包含主机名/地区等)解密后与 hash 比对
如果要验证签发机构公钥可信性的话, 会看看将签发机构信息进行hash, 并用签发机构的签发机构的公钥解密, 到最后公钥应该是系统内置的-
服务器公钥的签名
-
证书签发机构的公钥
-
证书签发机构的公钥的签名
-
证书签发机构的签发机构的公钥
-
证书签发机构的签发机构的公钥的签名
-
…..
-
根证书 (由系统自带)
-
-
Secret: 使用随机数使用服务端公钥加密生成 Master secrect / 客户端加密密钥 / 服务端加密密钥 / 客户端 MAC secrect / 服务端 MAC secrect
-
为什么不直接用公钥加密
目的: 防止中间人拦截后多次发送给服务端
-
客户端用服务端密钥加密发给服务端, 服务端用客户端密钥加密发给客户端
目的: 防止中间人将消息直接扔回
-
-
客户端通知:将使用加密通信 -
客户端发送:Finished -
服务器通知:将使用加密通信 -
服务器发送:Finished
-
-
Get和Post的区别:Post请求需要服务器返回100再发送数据, 速度会比Get略慢,Get请求不仅不会等待服务器返回100, 而且往往具有缓存, 性能较高. 如果抛开性能问题不谈, 我觉得大多数情况下产生的效果是一样的, 但是我们需要遵循RESTful方便团队协作 -
Retrofit的实现原理? 设计模式?
动态代理: 运行时代理, 起初我没看源码的时候我觉得 Retrofit 会像我们之前用的 butterKnife 是在编译期注解并生成方法的, 之后翻源码发现其实 Retrofit的注解是运行时注解, 采用动态代理的方式实现了网络请求

- 首先 Retrofit.create 是真正代码在的地方, 其他基本上都是接口
-
- 用 validateServiceInterface 验证传入的 class 是否是正常的 interface(比如说不能是泛型之类的)
- Proxy.newProxyInstance - InvocationHandler 的 invoke 并调用
loadServiceMethod- 对传入 Interface 中的注解进行
parseAnnotations得到 RequestFactory - 调用
HttpServiceMethod.parseAnnotations- 获取
CallAdapter(主要用于将 OkHttpCall 进行封装转换) (这里主要涉及是要同步还是异步返回以及对 kotlin suspend 的支持) 这里也提供了返回时使用 Handler 切换到主线程的功能 responseConverter: 这个是从 Builder 的时候传入的 ConverterFactory, 我们可以用这个将 response 对象转换成我们需要的对象 常用的有 GsonConverterFactory 以及 kotlin 这边用的更多的 MoshiConverterFactory- 之后使用
OkHttpCall进行真正的请求, 最终我们会通过之前的 CallAdapter 返回
- 获取
- 对传入 Interface 中的注解进行
okhttp咋实现的- 使用 Request Builder 模式传入
url,method,header,body等参数 - 使用 Request 构建 Call(
RealCall) (这里可以选择是否 WebSocket) - 从 client 获取 dispatcher, 调用
getResponseWithInterceptorChain将 OkhttpClient 中的拦截器组合成 InterceptorChain 调用链:RetryAndFollowUpInterceptor: 请求(realChain.proceed), 出错重试, 重定向BridgeInterceptor: 加各种 header(cookie) 什么的CacheInterceptor: 先找 Cache, 有的话使用 cache 参与构建 response, 否则请求并缓存然后返回ConnectInterceptor: 打开与目标服务器的连接, 其中创建了一个Exchange对象CallServerInterceptor: 去做真正的请求
- 使用 Request Builder 模式传入
View
-
有哪些布局: ConstraintLayout/FrameLayout/LinearLayout/RelativeLayout…GridLayout
-
Animation: 有三种:ViewAnimator: View.translation / xyz / rotation / scale / alphaObjectAnimator: ObjectAnimator.ofFloat / ofInt /ofArgb…帧动画: xml 文件内定义 animation-list 即可
-
ConstraintLayout优势- 灵活
- 相对定位
- 尺寸约束
- Chain
- 开发方便: 可视化的辅助工具
- 性能好: 减少嵌套
- 灵活
-
自定义view怎么进行屏幕适配: 使用 TypedValue, 下面是一个 dp转px 的示例, 这种和系统相关的资源(不涉及应用自身资源的)可以使用
Resources.getSystem()获取系统的resource进而获取displayMetrics1 2 3TypedValue.applyDimension( TypedValue.COMPLEX_UNIT_DIP, this.toFloat(), Resources.getSystem().displayMetrics ) -
屏幕是怎么绘制 View 的?
- View 的绘制就是接收父 View 调用其
measure, layout, draw方法 - 然后父 View 的绘制是通过它的父 View, 一路向上我们可以追溯到
ViewRootImpl的performTraversals()方法, 在其中包含了一个DecorView, 而 DecorView 含有状态栏, 导航栏, 以及我们 Activity 的显示区域, 这个显示区域是个 LinearLayout, 是由ViewStub和一个FrameLayout组成的 这个 FrameLayout 中就是一个 Activity 的真正显示的区域了 ViewRootImpl是通过WindowManagerGlobal的addView()方法创建出来的, 而 WindowManagerGlobal 其实是通过WindowManagerImpl调用的, WindowManagerImpl 是通过Activity创建的PhoneWindow对象进行getWindowManager()得到的
- View 的绘制就是接收父 View 调用其
-
RecyclerView和ListView缓存机制区别:- ListView 缓存 View, 离屏缓存, 从 mScrapViews 根据 pos 获取相应的缓存 getView 之后进行 bindView
- RecyclerView: 根据不同的 itemType 缓存不同的
ArrayList<ViewHolder>, 并存在四级缓存mAttachedScrap: 第一级缓存, 在 notifyXX() 预布局时储存不变的 holdermChangedScrap: 第一级缓存, 在预布局时存储改变的 holder, 用来根据新老 holder 执行 change 动画mCacheViews: 第二级缓存, 默认缓存 2 个 ItemView, 为避免多次 bindmViewCacheExtension: 第三级缓存, 需要开发者实现, 基本没用RecycledViewPool: 通过SparseArray<ArrayList<ViewHolder>>通过 SparseArray 实现的轻量 Map, 根据不同的 itemType 使用不同的缓存, 多个 RecyclerView 之间可以共享一个 RecycledViewPool
注: RecyclerView
Adapter主要有这些方法:onCreate/BindViewHolder,getItemViewType,getItemCount -
RecyclerView优化:- 分离视图绑定和数据处理: 尽量只在
onBindViewHolder中只设置数据或进行异步加载 分页延迟加载, 比如说使用 Paging 组件- 加大 RecyclerView.
mCachedViews的缓存 - 对于 RecycleView 的 Adapter 与其他 RecyclerView 相同的可以共享
RecyclerView.setRecycledViewPool(), 或者至少viewType不能冲突, 因为Recycler是根据viewType缓存的
- 分离视图绑定和数据处理: 尽量只在
-
触摸事件序列分发:
-
滑动冲突:
RecyclerView,ScrollView,ViewPager,ViewPager2,ListView…总之, 无非就这些讨论方面: 外部拦截, 内部拦截, 方向相同, 方向不同
requestDisallowInterceptTouchEvent通知父 View 禁止拦截canScrollVertically,canScrollHorizontally判断某个方向滑到头了- 自带解决方案:
NestedScrollView, 用多种viewType的RecyclerView - 自己解决:
onInterceptTouchEvent根据左右上下滑动的距离长短判断是不是应该拦截

Java基础
-
四种引用强引用: 哪怕触发 gc, 也抛出 OOM, 绝不回收软引用: 当内存空间足够, 垃圾回收器就不会回收它, 优先回收长期闲置不用的, 对于刚创建的’新’软引用尽可能保留, 如果回收完还没有足够的内存, OOM弱引用: 只能生存到下一次垃圾回收, 无论当前内存是否充足都会回收(适用于一个对象只是偶尔使用, 希望在使用时能随时获取, 但也不想影响对该对象的垃圾收集)虚引用: 如果一个对象仅持有虚引用, 那么它就和没有任何引用一样, 在任何时候都可能被垃圾回收(可以通过判断引用队列(ReferenceQueue)中是否已经加入了虚引用, 来了解被引用的对象是否将要被垃圾回收. 就可以在所引用的对象的内存被回收之前采取必要的行动)
-
JVM运行时的数据区: 方法区和堆(线程共享), 虚拟机栈和本地方法栈以及程序计数器(线程不共享, 随线程死亡而死亡, 因此不需要关注垃圾回收)JVM类加载: 加载, 连接(验证,准备,解析), 初始化, 使用, 卸载.双亲委托: 某个类加载时会自底向上检查一个类是否被加载, 如果没有就尝试自顶向下加载, 如果父类无法加载, 就将加载内容退回给下一层加载, 优点: 能有效确保一个类的全局唯一性 -
GC Root 有哪些: 虚拟机栈中引用的对象/活着的线程/Java 或 JNI 方法中的局部变量或参数/用于同步的监控对象(obj.wait()什么的)/被 jvm 持有的(SystemClassLoder和BootClassLoder)GC 清除算法有哪几种: 标记-清理, 复制(新生代), 标记-整理(老年代). -
如何理解
多态:运行时多态: 即重写(override): 子类向上转型后调用被子类重写过的父类的方法执行结果是子类重写后的, 这种要到运行时才知道具体执行什么方法编译时多态: 即重载(overload): 就是同一个类中出现了多个同名方法, 但他们参数类型或个数或顺序不同, 这种是编译期可以推断执行什么方法
-
OOM- 啥情况会出现
- 图片视频等大量消耗内存的场景
onDraw()里创建了大量对象- 内存泄漏导致占用内存大, 空闲内存不足导致 OOM (LeakCanary)
- 咋办?
- 采用
Glide或者LruCache, 或根据用户可用剩余内存大小去对Bitmap进行质量压缩(bitmap.compress采用RGB_565, 注意: 如果不改编码格式的话并不会改变内存占用, 但会减小二进制储存图片的尺寸), 采样率压缩(inSampleSize, inTargetDensity/inDensity), 并根据bitmap.allocationByteCount来判断内存占用是否符合要求 - 使用对象池复用一些对象
- 避免在
onDraw()中创建对象 - 谨慎使用
static对象 - 数据库
cursor不用时, 及时关闭 - 在一些情况下可以考虑更轻量的
SparseArray,ArrayMap用来替代HashMap等
- 采用
- 啥情况会出现
-
HashMapHashMap 1.7put(): 判断是否需要初始化 / 根据 key 计算 hash 定位出桶的位置 / 遍历链表查找是否有 key 与所需的相同, 如果相同替换掉, 不相同或者链表为空就用头插法插一个 Entry 到链表最前面, 此时如果链表大小超过桶大小, 两倍扩容并重新 hashHashMap 1.8put(): 判断是否需要初始化 / 根据 key 计算 hash 定位出桶的位置 / 链表或红黑树查找有没有这个 key, 有就替换, 没有的话如果是链表尾插法, 红黑树就按红黑树去插入 / 链表长度超过 8 且数组长度不小于 64 执行树化操作ConcurrentHashMap1.7 采用分段锁,HashEntry<K,V>和1.7的Entry<K,V>都是一样的功能, 都是数组加链表, 不同的是链表和核心数据都用volatile保证多线程的可见性了.Segment<K,V>继承自ReentrantLock
put(): 自旋获取锁, 达到最大次数时变成阻塞获取锁 / 定位到HashEntry的位置, 同1.7, 最后解除锁
-
注解:
@Retention: Source, Class, Runtime,@Target: Type, Field, Method, Parameter, Constructor, 本地变量LOCAL_VARIABLE, 注解注解类ANNOTATION_TYPE, 包声明Package. 常用注解: Override, Deprecated, SuppressWarnings -
泛型协变逆变; 在 kt 里,? extends相当于out,? super相当于in1 2ArrayList<? extends Object> objects = new ArrayList<String>(); // 协变 ArrayList<? super String> strings = new ArrayList<Object>(); // 逆变
四大组件
| Activity 生命周期 | Service 生命周期 |
|---|---|
|
|
默认四大组件在同一个进程中, 除非在 manifest 中显式指定android:process, 且都运行于主线程中
-
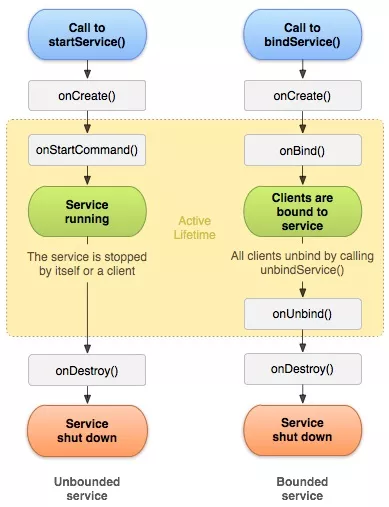
Service作用: 实现后台任务, 但是这个并不是一个子线程, 内部执行耗时操作你依然需要开子线程 -
Activity: 从 Launcher 点击应用图标到启动主要涉及:- Launcher 进程请求
AMS创建Application -> Activity AMS通过 Socket 请求 Zygote 通过 fork 自己创建进程并通知 AMS 创建完成, 然后整个 App 的入口方法就是ActivityThread.main, 然后执行 attach 进行createAppContext以及makeApplication, 这样 application 就会创建成功然后回调onCreate- 接下来
ActivityThread还会通过performLaunchActivity去创建Activity, 之后就是屏幕绘制的流程,Activity会创建PhoneWindow…(绘制流程在上面)
- Launcher 进程请求
-
Context是接口,ContextWrapper是 Context 的封装类, 而ContextImpl则是 Context 的实现类 -
Instrumentation: 管理Application,Service,Activity这些组件的创建以及它们的生命周期 -
Activity
LaunchMode: 推荐视频
我们在最近任务看到的任务并不是一个个的activity,也不是一个个的application, 事实上他们是以一个个的Task, 每个Task都是一个回退栈, 回退栈包含多个 activity, 当 Task 的最后一个 Activity 被弹出的时候, Task 也随之停止, 不过最近任务后台会留下这个Task的残影, 只不过再次点开这个Task的时候, 就不是回到之前的界面了, 而是重启 Activitystandard: 当你在 A App 里打开 B App 的 Activity 的时候, 这个 Activity 会直接被放进 A 的 Task 里, 而对于 B 的 Task 没有任何影响的
应用场景: 比如说我要添加个联系人, 添加个日程, 我们希望添加完以后可以返回原来 AppsingleTask: 当你在 A 里打开 B 的 Activity 的时候, Activity 会在属于它自己的 Task(B) 中打开, 并且将 Activity 上面的全部其他 Activity 全部弹出, 然后将整个 Task(B) 叠在之前的 Task(A) 之上, 此时如果查看一下最近任务, 叠在上面的 Task(B) 下来会成为一个单独的 Task
应用场景: 比如说我们在看文章, 这时 QQ 有个朋友分享了这个 App 里面的一篇文章给我, 此时我们希望的是我们看完这篇文章以后回到我之前看的那篇文章, 而不是退到 QQsingleInstance: 与 singleTask 基本一致, 只不过它会更加严格: 只允许一个 Task 里面有一个 Activity, 不允许在它上面有新的, 也不允许它下面有旧的
应用场景: 比如说应用调用支付宝付款这种被提供出来共享的 ActivitysingleTop: 它和默认一样, 也会把 Activity 创建之后加入到当前 Task 的栈顶, 唯一的区别是: 如果栈顶的这个 Activity 恰好就是要启动的 Activity, 那就不新建了而直接调用这个栈顶的 Activity 的 onNewIntent()???这launchmode有个鸡儿用啊
-
Activity切换动画:overridePendingTransition, 定义style, 使用ActivityOptions.makeSceneTransitionAnimation 并使用transitionName实现共享属性 -
Service 保活: 我觉得首先是你最好占用的资源小一点, 其次再去考虑其他方面.常见保活手段:
manifest中指定priority设置最高优先级, 启动的时候启动为前台Service,onDestory中发送广播然后接收广播唤醒, 监听系统广播(锁屏, WIFI状态改变)然后保活, 双 Service 保活, 还有向用户申请关闭电池优化, 以及针对不同厂商的不同手段 (比如说MIUI, EMUI) 去适配 -
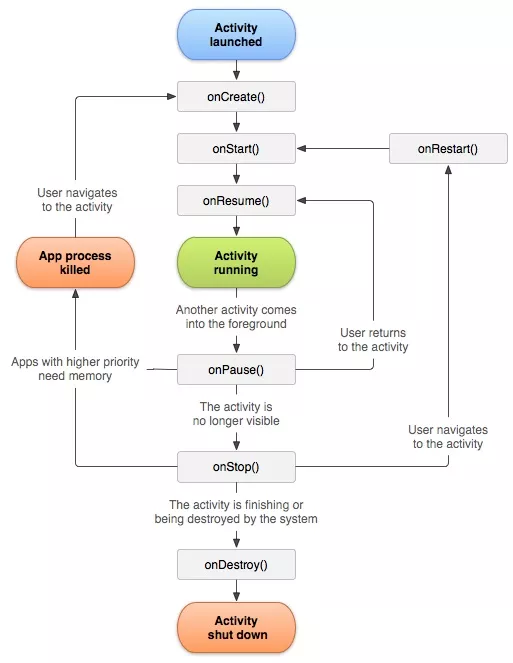
Activity生命周期:- Activity 第一次启动回调:
onCreate -> onStart -> onResume - 打开新的 Activity 或切换到桌面的时回调:
onPause -> onStop,如果新的采用透明主题,则原 Activity 的onStop不会回调 - 当用户再次回到原 Activity 时,回调如下:
onRestart -> onStart -> onResume - 当用户按下 back 键时,回调如下:
onPause -> onStop -> onDestroy - 就 Activity 整个生命周期来说,
onCreate和onDestroy是配对的;就 Activity 是否可见来说,onStart和onStop是配对的;就 Activity 是否在前台来说,onResume和onPause是配对的
- Activity 第一次启动回调:
-
Broadcast动态注册: 继承BroadcastReceiver,registReceiver(recevier,filter). 静态注册: manifest中声明recevier即可发送默认广播:
Context.sendBroadcast(), 有序广播:Context.sendOrderedBroadcast(), 有序广播可以提前处理广播并在必要时终止广播
编程基础
-
用过哪些设计模式有哪些设计模式: Factory/Builder/Singleton/Observer/Adapter/Proxy/Decorator/Template MethodFactory: 用来制造对象. 这里我主要用过的其实是 BitmapFactory, 它可以用来获取得到 Bitmap, 当然我们可以使用inJustDecodeBounds来只获取图片宽高并使用inSample,inDensity,inTargetDensity来加载合适尺寸的图片, 避免加载过大图片导致的 OOMBuilder: 当构造一个对象需要很多参数的时候, 并且参数的个数或类型不固定: 我常用到 AlertDialog 以及 OkhttpAdapter: 将一种类或一种接口转换成另一种类或者接口: 我们最常用到的就是 RecyclerView.Adapter 了, 将我们的数据转换成 ViewHolderSingleton: 比如说 Application, 详见:设计模式- 懒汉式: 调用时初始化 对应 kotlin lazy, (Java 最好的方案是使用内部静态类的常量去调用外部类的构造方法)
- 饿汉式: 提前实例化, 无懒加载
Observer: 比如说 RxJava, ObservableField, LiveData等
-
控制反转(IoC): 造汽车依赖于框架,框架需要有底盘,底盘需要依赖轮胎, 这样依赖会导致一旦我们换了轮胎之后,底盘/框架/汽车全都要改, 这样导致整个汽车设计全得动.
我们应该选择依赖反转, 根据要造的汽车得到框架,框架有给出底盘应该具有的规则,底盘给轮胎相应的规则, 这时候当我们想改轮胎的时候, 我们就可以只动轮胎了, 这样依赖关系就被倒转过来了
至于怎么实现: 可以用依赖注入实现, 比如说使用工厂类使用构造方法,setter, 这些全都可以用来依赖注入 -
MVC/MVP/MVVM:MVC: View 接收用户事件传给 Controller, 然后 Controller 去找 Model 层请求数据, 请求到之后 Model 层去刷新 ViewMVP: View 接收用户事件传给 Presenter, 然后 Presenter 去请求 Model 层获取数据, 请求到之后 Presenter 层通过回调接口去刷新 ViewMVVM: 将 View 与 Model 通过 ViewModel 进行绑定, 当 Model 层发生变化自动刷新到 View, Jetpack 提供了 DataBinding 这套工具来简化了我们的自动绑定
-
什么是
事务? 怎么理解事务? 事务是并发控制的基本单位事务应该具有4个属性:原子性、一致性、隔离性、持久性
原子性(atomicity):事务是最小的执行单位
一致性(consistency): 多个事务对同一个数据读取的结果是相同的
隔离性(isolation):并发访问时, 一个事务不被其他事务干扰, 各并发事务之间是独立的
持久性(durability):事务被提交之后对数据的改变是持久的
-
怎么理解
面向对象: 封装(隐藏内部属性行为提高安全性)、继承(提高代码复用性和可维护性)、多态 -
抽象类和接口有什么区别呢?抽象类可以有默认实现, 而子类进行继承. 接口本身什么事情都干不了 接口是为了方便某个类去开放一些方法, 而抽象类是为了方便同种的类去实现这一类功能
-
Linux
多进程通信: 有名管道, 无名管道, 共享内存, 信息, 信息量, 套接字 -
Android
多进程通信的几种方式?Binder: 需要拷贝一次, 基于 C/S(Client/Server) 架构, 为每个 App 分配 UID, 同时支持实名和匿名. 我们只需要处理客户端的拷贝, 对于服务端我们不需要做很复杂的处理, 易用性高共享内存: 无需拷贝, 控制复杂, 易用性差, 我们可以类比 Android 的多线程控制, 多线程控制需要去处理什么同步问题. 访问接入点是开放的, 不安全Socket: 需要拷贝两次, 基于 C/S 架构, 传输效率低, 访问接入点是开放的, 不安全
-
基本 sql 语句
1 2 3 4 5delete from students where gender='M'; insert into students (name,gender,score) values ('wrnm','K',10); update students set name='nb',gender='F',score=10000 where score<20; select * from students order by score desc limit 3 offset 0; create index index_name on table_name (column_name)
其他
-
不用第三方库, 自己尝试读取Bitmap, 需要注意哪些问题(OOM和LRUCache)
- 针对不同大小的 View 按照大小读取图片 (inJustDecodeBounds/inDensity/targetDensity)
- 使用 LruCache
-
Serializable与Parcelable: 如果只用于内存不储存到本地不传输到网络, 只用于Intent和Binder之间传输, 那么不需要使用 Serializable, 使用 Parcelable 性能更高 -
Kotlin: let, with, run, apply, also:
this系:this.run:{},this.apply:this,with(this):{}it系:this.let:{},this.also:this -
Glide 简单知识-
内存 - 磁盘 - 网络 三级加载 (内存分为 ActiveResource 和 Cache(LruCache))
-
内存分为
Map<Key, ResourceWeakReference>以及LruCache<Key, Resource<?>> -
磁盘缓存策略:
DiskCacheStrategy.DATA:只缓存原始内容DiskCacheStrategy.NONE: 不缓存任何内容DiskCacheStrategy.RESOURCE:只缓存转换过后的图片(经过decode,转化裁剪的图片)DiskCacheStrategy.ALL: 既缓存原始图片, 也缓存转换过后的图片. 对于远程图片, 缓存DATA和RESOURCE. 对于本地图片, 只缓存RESOURCE.DiskCacheStrategy.AUTOMATIC(默认策略):加载远程数据时, 仅存储原始数据(因为下载远程数据相比调整磁盘上已经存在的数据要昂贵得多), 而对于本地数据, 仅存储变换过的缩略图(RESOURCE), 因为即使你需要再次生成另一个尺寸或类型的图片, 取回原始数据也很容易
主要流程:
with: 创建RequestManagerRetriever, 然后根据传入context类型, 如果是Activity的话就创建一个空fragment来检测activity的生命周期, 如果是后台线程或者是applicationContext的话就使用全局生命周期, 然后构建RequestManager.load: 使用RequestManager构建RequestBuilder, 这里还会指定asBitmap,asFile,asGif,asDrawable什么的into: 可以传入一个target或者是imageView, 事实上imageView传入进去也会变成ViewTarget, 然后buildRequest, 接着requestManager就会去track->runRequest启动图片请求, 不过这里会进行一下判断, 因为之前我们通过requestManager获取到了生命周期, 如果是后台省电模式状态什么的就会先加入一个pendingRequests, 后续再进行请求.- 之后会调用
Request接口的begin, 实质上的话会去调onSizeReady, 然后就去engine.load执行真正的请求, 这里会将传入的参数生成一个key, 然后依次从ActiveResources,LruCache(默认),磁盘缓存里面去找, 找不到就创建EngineJob然后使用Executor去网络请求
-
AIDL: 接口定义语言, 与 Java 一致, 只支持基本数据类型和 String. 基于Binder, 服务端需要实现Interface.Stub(这玩意其实是继承Binder的)并重写接口定义的方法. 客户端需要在创建的connection对象里面onServiceConnect里通过Interface.Stub.asInterface方法建立访问 -
Bitmap储存位置: Android2.2(Java堆), Android 2.3(并发gc), Android 3.0-7.1(储存在Dalvik堆), 8.0+(native堆中, 但会随着Java对象回收而回收)
-